

Need to let loose a primal scream without collecting footnotes first? Have a sneer percolating in your system but not enough time/energy to make a whole post about it? Go forth and be mid: Welcome to the Stubsack, your first port of call for learning fresh Awful you’ll near-instantly regret.
Any awful.systems sub may be subsneered in this subthread, techtakes or no.
If your sneer seems higher quality than you thought, feel free to cut’n’paste it into its own post — there’s no quota for posting and the bar really isn’t that high.
The post Xitter web has spawned soo many “esoteric” right wing freaks, but there’s no appropriate sneer-space for them. I’m talking redscare-ish, reality challenged “culture critics” who write about everything but understand nothing. I’m talking about reply-guys who make the same 6 tweets about the same 3 subjects. They’re inescapable at this point, yet I don’t see them mocked (as much as they should be)
Like, there was one dude a while back who insisted that women couldn’t be surgeons because they didn’t believe in the moon or in stars? I think each and every one of these guys is uniquely fucked up and if I can’t escape them, I would love to sneer at them.
I’ve often called slop “signal-shaped noise”. I think the damage already done by slop pissed all over the reservoirs of knowledge, art and culture is irreversible and long-lasting. This is the only thing generative “AI” is good at, making spam that’s hard to detect.
It occurs to me that one way to frame this technology is as a precise inversion of Bayesian spam filters for email; no more and no less. I remember how it was a small revolution, in the arms race against spammers, when statistical methods came up; everywhere we took of the load of straining SpamAssassin with rspamd (in the years before gmail devoured us all). I would argue “A Plan for Spam” launched Paul Graham’s notoriety, much more than the Lisp web stores he was so proud of. Filtering emails by keywords was not being enough, and now you could train your computer to gradually recognise emails that looked off, for whatever definition of “off” worked for your specific inbox.
Now we have the richest people building the most expensive, energy-intensive superclusters to use the same statistical methods the other way around, to generate spam that looks like not-spam, and is therefore immune to all filtering strategies we had developed. That same blob-like malleability of spam filters makes the new spam generators able to fit their output to whatever niche they want to pollute; the noise can be shaped like any signal.
I wonder what PG is saying about gen-“AI” these days? let’s check:
“AI is the exact opposite of a solution in search of a problem,” he wrote on X. “It’s the solution to far more problems than its developers even knew existed … AI is turning out to be the missing piece in a large number of important, almost-completed puzzles.”
He shared no examples, but […]Who would have thought that A Plan for Spam was, all along, a plan for spam.
It occurs to me that one way to frame this technology is as a precise inversion of Bayesian spam filters for email.
This is a really good observation, and while I had lowkey noticed it (one of those feeling things), I never had verbalized it in anyway. Good point imho. Also in how it bypasses and wrecks the old anti-spam protections. It represents a fundamental flipping of sides of the tech industry. While before they were anti-spam it is now pro-spam. A big betrayal of consumers/users/humanity.
Signal shaped noise reminds me of a wiener filter.
Aside: when I took my signals processing course, the professor kept drawing diagrams that were eerily phallic. Those were the most memorable parts of the course
Idea: a programming language that controls how many times a for loop cycles by the number of times a letter appears in a given word, e.g., “for each b in blueberry”.
And the language’s main data container is a kind of stack, but to push or pop values, you have to wrap them into “boats” which have to cross a “river”, with extra rules for ordering and combination of values.
sickos.jpg
Only dutch/german people can create the very long loops.
E: I’m reminded of the upcoming game called: “Planetenverteidigungskanonenkommandant”
for e in rindfleischetikettierungsüberwachungsgesetz@mlen @Soyweiser * für e […] 🤓
for h in Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
you’d think so, until outsourcing to turkish subcontractor happens
for ä in epäjärjestelmällistyttämättömyydelläänsäkäänköhänEveryone else has to
#appropriatetheirculture.You can take my bitterballen from my WARM FRIENDLY HANDS! No really try some, there are also vegetarian variants.
(They are part of the Inventaris Immaterieel Cultureel Erfgoed Nederland (Inventory of Intangible Cultural Heritage of the Netherlands), only 2 loops though)

image contents
will arnett from arrested development asking “bees?!”
Beads.
Is it a loop if it only executes once?
Time for some Set Theory!
… but the output is not deterministic as the letter count is sampled from a distribution of possible letter counts for a given word and letter pair; count ~ p(count | word = “blueberry”, letter = ‘b’)!
Even bigger picture… some standardized way of regularly handling possible combinations of letters and numbers that you could use across multiple languages. Like it handles them as expressions?
Ozy Brennan tries to explain why “rationalism” spawns so many cults.
One of the reasons they give is “a dangerous sense of grandiosity”.
the actual process of saving the world is not very glamorous. It involves filling out paperwork, making small tweaks to code, running A/B tests on Twitter posts.
Yep, you heard it right. Shitposting and inconsequential code are the proper way to save the world.
JFC
Agency and taking ideas seriously aren’t bad. Rationalists came to correct views about the COVID-19 pandemic while many others were saying masks didn’t work and only hypochondriacs worried about covid; rationalists were some of the first people to warn about the threat of artificial intelligence.
First off, anyone not entirely into MAGA/Qanon agreed that masks probably helped more than hurt. Saying rats were outliers is ludicrous.
Second, rats don’t take real threats of GenAI seriously - infosphere pollution, surveillance, autopropaganda - they just care about the magical future Sky Robot.
deleted by creator
That’s how I remember it too. Also the context about conserving N95 masks always feels like it gets lost. Like, predictably so and I think there’s definitely room to criticize the CDC’s messaging and handling there, but the actual facts here aren’t as absurd as the current fight would imply. The argument was:
- With the small droplet size, most basic fabric masks offer very limited protection, if any.
- The masks that are effective, like N95 masks, are only available in very limited quantities.
- If everyone panic-buys N95 the way they did toilet paper it will mean that the people who are least able to avoid exposure i.e. doctors and medical frontliners are at best going to wildly overpay and at worst won’t be able to keep supplied.
- Therefore, most people shouldn’t worry about masking at this stage, and focus on other measures like social distancing and staying the fuck home.
I think later research cast some doubt on point 1, but 2-4 are still pretty solid given the circumstances that we (collectively) found ourselves in.
Meanwhile, the right-wing prepper types were breaking out the N95 masks they’d stockpiled for a pandemic
This included Scott ssc btw. Who also claimed that stopping smoking helped against cov. Not that he had any proof (the medical science at the time even falsely (it came out later) claimed smoking helped agains covid). But only the CDC gets judged, not the ingroup.
And other Scott blamed people who sneer for making covid worse. (While at sneerclub we were going, take this seriously and wear a mask).
So annoying Rationalists are trying to spin this into a win for themselves. (They also were not early, their warnings matched the warnings of the WHO, looked into the timelines last time this was talked about).
But doctor, I am L7 twitter manager Pagliacci
oldskool OSI appmanager is oldskool
(…sorry)
I’m gonna need this one explained, boss
(in networking it’s common terminology to refer to “Lx” by numerical reference, and broadly understood to be in reference to this)
Aaaaa gotcha. It’s probably obvious but in my case I meant L7 manager as in “level 7 manager”, a high tier managerial position at twitter, probably. I don’t know what exact tiering system twitter uses but I know other companies might use “Lx” to designate a level.
I figured, but I couldn’t just let a terrible pun slip me by!
Overall more interesting than I expected. On the Leverage Research cult:
Routine tasks, such as deciding whose turn it was to pick up the groceries, required working around other people’s beliefs in demons, magic, and other paranormal phenomena. Eventually these beliefs collided with preexisting social conflict, and Leverage broke apart into factions that fought with each other internally through occult rituals.
They sure don’t make rationalism like they used to.
So… apparently Peter Thiel has taken to co-opting fundamentalist Christian terminology to go after Effective Altruism? At least it seems that way from this EA post (warning, I took psychic damage just skimming the lunacy). As far as I can tell, he’s merely co-opting the terminology, Thiel’s blather doesn’t have any connection to any variant of Christian eschatology (whether mainstream or fundamentalist or even obscure wacky fundamentalist), but of course, the majority of the EAs don’t recognize that, or the fact that he is probably targeting them for their (kind of weak to be honest) attempts at getting AI regulated at all, and instead they charitably try to steelman him and figure out if he was a legitimate point. …I wish they could put a tenth of this effort into understanding leftist thought.
Some of the comments are… okay actually, at least by EA standards, but there are still plenty of people willing to defend Thiel
One comment notes some confusion:
I’m still confused about the overall shape of what Thiel believes.
He’s concerned about the antichrist opposing Jesus during Armageddon. But afaik standard theology says that Jesus will win for certain. And revelation says the world will be in disarray and moral decay when the Second Coming happens.
If chaos is inevitable and necessary for Jesus’ return, why is expanding the pre-apocalyptic era with growth/prosperity so important to him?
Yeah, its because he is simply borrowing Christian Fundamentalists Eschatological terminology… possibly to try to turn the Christofascists against EA?
I’m dubious Thiel is actually an ally to anyone worried about permanent dictatorship. He has connections to openly anti-democratic neoreactionaries like Curtis Yarvin, he quotes Nazi lawyer and democracy critic Carl Schmitt on how moments of greatness in politics are when you see your enemy as an enemy, and one of the most famous things he ever said is “I no longer believe that freedom and democracy are compatible”. Rather I think he is using “totalitarian” to refer to any situation where the government is less economically libertarian than he would like, or “woke” ideas are popular amongst elite tastemakers, even if the polity this is all occurring in is clearly a liberal democracy, not a totalitarian state.
Note this commenter still uses non-confrontational language (“I’m dubious”) even when directly calling Thiel out.
The top comment, though, is just like the main post, extending charitability to complete technofascist insanity. (Warning for psychic damage)
Nice post! I am a pretty close follower of the Thiel Cinematic Universe (ie his various interviews, essays, etc)
I think Thiel is also personally quite motivated (understandably) by wanting to avoid death. This obviously relates to a kind of accelerationist take on AI that sets him against EA, but again, there’s a deeper philosophical difference here. Classic Yudkowsky essays (and a memorable Bostrom short story, video adaptation here) share this strident anti-death, pro-medical-progress attitude (cryonics, etc), as do some philanthropists like Vitalik Buterin. But these days, you don’t hear so much about “FDA delenda est” or anti-aging research from effective altruism. Perhaps there are valid reasons for this (low tractability, perhaps). But some of the arguments given by EAs against aging’s importance are a little weak, IMO (more on this later) – in Thiel’s view, maybe suspiciously weak. This is a weird thing to say, but I think to Thiel, EA looks like a fundamentally statist / fascist ideology, insofar as it is seeking to place the state in a position of central importance, with human individuality / agency / consciousness pushed aside.
As for my personal take on Thiel’s views – I’m often disappointed at the sloppiness (blunt-ness? or low-decoupling-ness?) of his criticisms, which attack the EA for having a problematic “vibe” and political alignment, but without digging into any specific technical points of disagreement. But I do think some of his higher-level, vibe-based critiques have a point.
tl,dr; Thiel now sees the Christofascists as a more durable grifting base than the EAs, and is looking to change lanes while the temporary coalitions of maximalist Trumpism offer him the opportunity.
I repeat my suspicion that Thiel is not any more sober than Musk, he’s just getting sloppier about keeping it out of the public eye.
I think a big difference between Thiel and Musk, is that Thiel views himself as an “intellectual” and derives prestige “intellectualism”. I don’t believe for a minute he’s genuinely christian, but his wankery about end-of-times eschatology of armageddon = big-left-government, is a a bit too confused to be purely cynical, I think sniffing his own farts feeds his ego.
Of course a man who would promote open doping olympics isn’t sober.
Yeah, its because he is simply borrowing Christian Fundamentalists Eschatological terminology… possibly to try to turn the Christofascists against EA?
Yep, the usefulness of EA is over, they are next on the chopping block. I’d imagine a similar thing will happen to redscare/moldbug if they ever speak out against him.
E: And why would a rich guy be against a “we are trying to convince rich guys to spend their money differently” organization. Esp a ‘libertarian’ “I get to do what I want or else” one.
It always struck me as hilarious that the EA/LW crowd could ever affect policy in any way. They’re cosplaying as activists, have no ideas about how to move the public image needle other than weird movie ideas and hope, and are literally marinated in SV technolibertarianism which sees government regulation as Evil.
There’s a mini-freakout over OpenAI deciding to keep GPT-4o active, despite it being more “sycophantic” than GPT-5 (and thus more likely to convince people to do Bad Things) but there’s also the queasy realization that if sycophantic LLMs is what brings in the bucks, nothing is gonna stop LLM companies from offering them. And there’s no way these people can stop it, because they’ve made the deal that LLM companies are gonna be the ones realizing that AI is gonna kill everyone and that’s never gonna happen.
They’re cosplaying as activists, have no ideas about how to move the public image needle other than weird movie ideas and hope, and are literally marinated in SV technolibertarianism which sees government regulation as Evil.
It is kind of sad. They are missing the ideological pieces that would let them carry out activism effectually so instead they’ve gotten used as a free source of crit-hype in the LLM bubble. …except not that sad because they would ignore real AI dangers in favor of their sci-fi scenarios, so I don’t feel too bad for them.
Brian Merchant’s article about that lighthaven gathering really struck me.
The men who EAs think will end the earth were in the building with them, and rather than organize to throw them out a window (or even to just make them mildly uncomfortable), the bayes knowers all gormlessly moped around their twee boutique hotel and cried around some whiteboards.
Absolute hellish brainworms
Yeah that article was one of the things I had mind. It’s the peak of centrist liberalism where EAs and lesswrongers can think these people are literally going to cause mankind’s extinction (or worse) and they can’t even bring themselves to be rude to them. OTOH, if they actually acted coherently on their nominal doomer beliefs, they would be carrying out terrorism on a far greater scale than the Zizians, so maybe it is for the best they are ideologically incapable of direct action.
The ideological version of Mr Burns’s diseases getting in each other’s way
Ooh, do you have a link to share?
Wild, thank you!
And why would a rich guy be against a “we are trying to convince rich guys to spend their money differently” organization.
Well when they are just passively trying to convince the rich guys, they can use the organization to launder reputation or boost ideologies they are in favor of. When the organization actually tries to get regulations passed, even ineffectually, well, that is a threat to the likes of Thiel.
That was what I meant, I was being a bit sarcastic there.
Thiel is a true believer in Jesus and God. He was raised evangelical. The quirky eschatologist that you’re looking for is René Girard, who he personally met at some point. For more details, check out the Behind the Bastards on him.
Edit: I wrote this before clicking on the LW post. This is a decent summary of Girard’s claims as well as how they influence Thiel. I’m quoting West here in order to sneer at Thiel:
Unfortunately (?), Christian society does not let us sacrifice random scapegoats, so we are trapped in an ever-escalating cycle, with only poor substitutes like “cancelling celebrities on Twitter” to release pressure. Girard doesn’t know what to do about this.
Thiel knows what to do about this. After all, he funded Bollea v. Gawker. Instead of letting journalists cancel celebrities, why not cancel journalists instead? Then there’s no longer any journalists to do any cancellation! Similarly, Thiel is confirmed to be a source of funding for Eric Weinstein and believed to fund Sabine Hossenfelder. Instead of letting scientists cancel religious beliefs, why not cancel scientists instead? By directing money through folks with existing social legitimacy, Thiel applies mimesis: pretend to be legitimate and you can shift what is legitimate.
In this context, Thiel fears the spectre of AGI because it can’t be influenced by his normal approach to power, which is to hide anything that can be hidden and outspend everybody else talking in the open. After all, if AGI is truly to unify humanity, it must unify our moralities and cultures into a single uniformly-acceptable code of conduct. But the only acceptable unification for Thiel is the holistic catholic apostolic one-and-only forever-and-ever church of Jesus, and if AGI is against that then AGI is against Jesus himself.
Is there any more solid evidence of Hossenfelder taking Thielbux, or is this just a guess based on the orbit she moves in: appearing on Michael Shermer’s podcast years after the news broke that he was a sex pest, blurbing the new book edited by sex pest Lawrence Krauss, etc.
There’s no solid evidence. (You can put away the attorney, Mr. Thiel.) Experts in the field, in a recent series of interviews with Dave Farina, generally agree that somebody must be funding Hossenfelder. Right now she’s associated with the Center for Mathematical Philosophy at LMU Munich; her biography there is pretty funny:
Sabine’s current research interest focuses on the role of locality and finetuning in theory development. Locality has been widely considered a lost cause in the foundations of quantum mechanics. A basically unexplored way to maintain locality, however, is the idea of superdeterminism, which has more recently also been re-considered under the name “contextuality”. Superdeterminism is widely believed to be finetuned. One of Sabine’s current research topics is to explore whether this belief is justified. The other main avenue she is pursuing is how superdeterminism can be experimentally tested.
For those not in physics: this is crank shit. To the extent that MCMP funds her at all, they are explicitly pursuing superdeterminism, which is unfalsifiable, unverifiable, doesn’t accord with the web of science, and generally fails to be a serious line of inquiry. Now, does MCMP have enough cash to pay her to make Youtube videos and go on podcasts? We don’t know. So it’s hard to say whether she has funding beyond that.
Oh, wow, that biography is hilariously bad. Contexuality is not the same thing as superdeterminism. And locality is not “a lost cause”. Plenty of people throw around the term quantum nonlocality, but in the smaller population of those who take foundations seriously, many will say that quantum mechanics is local. Most but not all proponents of Copenhagen-ish interpretations say something like, “The moral of Bell’s theorem is that nature needs a non-(local hidden variable) theory. We keep locality and drop the hidden variables. In other words, quantum physics is a local non-(hidden variable) theory.” The Everettians of various flavors also tend to hold onto locality, or try to, while not always agreeing with each other on how to do that. It’s probably only among the Bohmians that you’ll find people insisting that quantum physics means nature is intrinsically nonlocal.
The quirky eschatologist that you’re looking for is René Girard, who he personally met at some point. For more details, check out the Behind the Bastards on him.
Thanks for the references. The quirky theology was so outside the range of even the weirder Fundamentalist Christian stuff I didn’t recognize it as such. (And didn’t trust the EA summary because they try so hard to charitably make sense of Thiel).
In this context, Thiel fears the spectre of AGI because it can’t be influenced by his normal approach to power, which is to hide anything that can be hidden and outspend everybody else talking in the open.
Except the EAs are, on net, opposed to the creation of AGI (albeit they are ineffectual in their opposition). So going after the EAs doesn’t make sense if Thiel is genuinely opposed to inventing AGI faster. So I still think Thiel is just going after the EA’s because he’s libertarian and EA has shifted in the direction of trying to get more government regulation. (As opposed to a coherent theological goal beyond libertarianism). I’ll check out the BtB podcast and see if it changes my mind as to his exact flavor of insanity.
Thiel is a true believer in Jesus and God. He was raised evangelical.
Being gay must really complicate things for him.
Using the term “Antichrist” as a shorthand for “global stable totalitarianism” is A Choice.
I think Leathery Pete might have read too much Left Behind.
Thomasaurus has given their thoughts on using AI, in a journal entry called “I tried coding with AI, I became lazy and stupid)”. Unsurprisingly, the whole thing is one long sneer, with a damning indictment of its effectiveness at the end:
If I lose my job due to AI, it will be because I used it so much it made me lazy and stupid to the point where another human has to replace me and I become unemployable.
I shouldn’t invest time in AI. I should invest more time studying new things that interest me. That’s probably the only way to keep doing this job and, you know, be safe.
New article from the New York Times reporting on an influx of compsci graduates struggling to find jobs (ostensibly caused by AI automation). Found a real money shot about a quarter of the way through:
Among college graduates ages 22 to 27, computer science and computer engineering majors are facing some of the highest unemployment rates, 6.1 percent and 7.5 percent respectively, according to a report from the Federal Reserve Bank of New York. That is more than double the unemployment rate among recent biology and art history graduates, which is just 3 percent.
You want my take, I expect this article’s gonna blow a major hole in STEM’s public image - being a path to a high-paying job was one of STEM’s major selling points (especially compared to the “useless” art/humanities degrees), and this new article not only undermines that selling point, but argues for flipping it on its head.
Quick update: I’ve checked the response on Bluesky, and it seems the general response is of schadenfreude at STEM’s expense. From the replies, I’ve found:
-
Humanities graduates directly mocking STEM (Fig. 1,Fig. 2, Fig. 3, Fig. 4, Fig. 5)
-
Mockery of the long-running “learn to code” mantra (Fig. 1, Fig. 2, Fig. 3, Fig. 4 Fig. 5, Fig. 6)
-
Claims that STEM automated themselves out of a job by creating AI (Fig. 1, Fig. 2, Fig. 3)
Plus one user mocking STEM in general as “[choosing] fascism and “billions must die”” out of greed, and another approving of others’ dunks on STEM over past degree-related grievances.
You want my take on this dunkfest, this suggests STEM’s been hit with a double-whammy here - not only has STEM lost the status their “high-paying” reputation gave them, but that reputation (plus a lotta built-up grievances from mockery of the humanities) has crippled STEM’s ability to garner sympathy for their current predicament.
I hate the fact that now someone might look at me and surmise that I do something related to blockchain or AI, I feel almost like I need a sticker, like those “I bought it before we knew Elon was crazy” they put on Teslas
“I learnt to code before this stupid bubble”
stolen from cohost but i appreciate the succinctness of “capitalism make computer bad”
On one hand, this is another case of capitalism working as intended. You have the ruling class dangling the carrot of the promise of social mobility via job. Just gotta turn the crank of the orphan grinder for 4 years or so, until there’s enough orphan paste to grease the next grinding machine. But it’s ok, because your experience in crank will let you climb the ladder to the next, higher paying, higher prestige crank of the machine. Then one day, they decide to turn on the motor.
On the other hand? There is no other hand, they chopped it off because you didn’t turn the crank fast enough when you had the chance.
To extend that analogy a bit, the dunkfest I noted suggests that a portion of the public views STEM as perfectly okay with the orphan grinder’s existence at best, and proud of having orphan blood on their hands at worst.
As for the motorised orphan grinder you mention, it looks to me like the public viewed its construction as STEM voting for the Leopards Eating People’s Faces Party (with predictable consequences).
The whole joining of the fascist side by a lot of the higher ups of the tech world, combined with the long-standing debate bro both sides free speech libertarianism (but mostly for neonazis, payment services do go after sex work and lgbt content) also did not help the rep of STEM, even if those decisions are made by STEM curious people and not actually STEM people. billionaires want you to know they could have done physics - Angela Collier
You’re dead right on that.
Part of me suspects STEM in general (primarily tech, the other disciplines look well-protected from the fallout) will have to deal with cleaning off the stench of Eau de Fash after the dust settles, with tech in particular viewed as unequipped to resist fascism at best and out-and-proud fascists at worst.
you say STEM, but you seem to mean almost exclusively computer touchers, already mentioned biologists or variety of engineers won’t likely have these problems (i’m not gonna be excessively smug about this because my field will destroy you physically while still being STEM and not particularly glorious)
also it’s not a complete jobocalypse, there’s still 93% employed fresh CS grads, they might have comparatively shittier jobs, but it’s not a disaster (unless picture is actually much bleaker in that that unemployment is, say, concentrated in last 2 years of graduates, but still even in this case it’s maybe 10%, 12% tops for the worst affected). unless you mean their unlimited libertarian flavoured greed coming through it, then yeah, it’s pretty funny
even then, there’s gonna be a funny rebound when these all genai companies implode, partially maybe not in top earner countries, but places like eastern europe or india will fill that openai-sized crater pretty handily, if that mythical outsourcing to ai happened in the first place, that is
As an aging dev, we kind of do deserve some of this flak lol. Funny thing is, I went into SD because my first STEM degree made me as unemployable as a humanities major (a B.S. in physics is good for not much).
-
Well, what’s next, and how much work is it? I didn’t want to be a computing professional. I trained as a jazz pianist. At some point we ought to focus on the real problem: not STEM, not humanities, but business schools and MBA programs.
Well, what’s next, and how much work is it?
I’m not particularly sure myself. By my guess, I don’t expect one specific profession to be “what’s next”, but a wide variety of professions becoming highly lucrative, primarily those which can exploit the fallout of the AI bubble to their benefit. Giving some predictions:
-
Therapists and psychiatrists should find plenty of demand, as mental health crisis and cases of AI psychosis provide them a steady stream of clients.
-
Those in writing related jobs (e.g. copywriters) can likely squeeze hefty premiums from clients with AI-written work that needs fixing.
-
Programmers may find themselves a job tearing down the mountains of technical debt introduced by vibe-coding, and can probably crowbar a premium out of desperate clients as well. (This one’s probably gonna be limited to senior coders, though - juniors are likely getting the shaft on this front)
As for which degrees will come into high demand, I expect it will be mainly humanities degrees that benefit - either directly through netting you a profession that can exploit the AI fallout, or indirectly through showing you have skills that an LLM can’t imitate.
I didn’t want to be a computing professional. I trained as a jazz pianist
Nice. You could probably earn some cash doing that on the side.
At some point we ought to focus on the real problem: not STEM, not humanities, but business schools and MBA programs.
You’re goddamn right.
-
Except biology isn’t being hit as badly and that’s also STEM. I wouldn’t be surprised if other life sciences have also done better, at least until Trump started fucking with the grant system.
It’s specifically computer-touchers who are in the toilet.
deleted by creator
Yall ready for another round of LessWrong edit wars on Wikipedia? This time with a wider list of topics!
On the very slightly merciful upside… the lesswronger recommends “If you want to work on a new page, discuss with the community first by going to the talk page of a related topic or meta-page.” and “In general, you shouldn’t post before you understand Wikipedia rules, norms, and guidelines.” so they are ahead of the previous calls made on Lesswrong for Wikipedia edit-wars.
On the downside, they’ve got a laundry list of lesswrong jargon they want Wikipedia articles for. Even one of the lesswrongers responding to them points out these terms are a bit on the under-defined side:
Speaking as a self-identified agent foundations researcher, I don’t think agent foundations can be said to exist yet. It’s more of an aspiration than a field. If someone wrote a wikipedia page for it, it would just be that person’s opinion on what agent foundations should look like.
PS: We also think that there existing a wiki page for the field that one is working in increases one’s credibility to outsiders - i.e. if you tell someone that you’re working in AI Control, and the only pages linked are from LessWrong and Arxiv, this might not be a good look.
Aha so OP is just hoping no one will bother reading the sources listed on the article…
Looking to exploit citogenesis for political gain.
I could imagine a lesswronger being delusional/optimistic enough to assume their lesswrong jargon concepts have more academic citations than a handful of arXiv preprints… but in this case they just admitted otherwise their only sources are lesswrong and arXiv. Also, if they know wikipedia’s policies, they should no the No Original Research rule would block their idea even overlooking single source and conflict of interest.
From the comments:
On the contrary, I think that almost all people and institutions that don’t currently have a Wikipedia article should not want one.
Huh. How oddly sensible.
An extreme (and close-to-home) example is documented in TracingWoodgrains’s exposé.of David Gerard’s Wikipedia smear campaign against LessWrong and related topics.
Ah, never mind.
I finally steeled myself to look at the page history. After dgerard commented about it, someone else tagged the article for additional problems:
-
This article contains wording that promotes the subject in a subjective manner without imparting real information. (August 2025)
-
This article may be too technical for most readers to understand. (August 2025)
Then a third editor added a section … made of LLM bullshit.
I’d probably be exaggerating if I said that every time I looked under the hood of Wikipedia, it reaffirmed how I don’t have the temperament to edit there. But I wouldn’t be exaggerating by much. It’s enough of a hassle to agree upon text in a paper co-authored with a colleague I know personally and like. Dealing with posers whose ego pays them by the word… Ugh.
I’d probably be exaggerating if I said that every time I looked under the hood of Wikipedia, it reaffirmed how I don’t have the temperament to edit there.
The lesswrongers hate dgerad’s Wikipedia work because they perceive it as calling them out, but if anything Wikipedia’s norms makes his “call outs” downright gentle and routine.
-
We’re at the point of 100xers giving themselves broken sleep schedules so they can spend tokens optimally.
Inevitably, Anthropic will increase their subscription costs or further restrict usage limits. It feels like they’re giving compute away for free at this point. So when the investor bux start to run dry, I will be ready.
This has to be satire, but oh my god.
I’m sorry in advance for posting this meme.

My velocity has increased 10x and I’m shipping features like a cracked ninja now, which is great because my B2B SaaS is still in stealth mode.
Yeah it’s satire, but effective satire means you can never really tell…
Im old enough to recall the polyphasic sleep fad. And how that wrecked people if they ever messed up. (Iirc also turns out very bad implications for long term health).
Tante fires off about web search:
There used to be this deal between Google (and other search engines) and the Web: You get to index our stuff, show ads next to them but you link our work. AI Overview and Perplexity and all these systems cancel that deal.
And maybe - for a while - search will also need to die a bit? Make the whole web uncrawlable. Refuse any bots. As an act of resistance to the tech sector as a whole.
On a personal sidenote, part of me suspects webrings and web directories will see a boost in popularity in the coming years - with web search in the shitter and AI crawlers being a major threat, they’re likely your safest and most reliable method of bringing human traffic to your personal site/blog.
Mastodon post linking to the least shocking Ars lede I have seen in a bit. Apparently “reasoning” and “chain of thought” functionality might have been entirely marketing fluff? :shocked pikachu:
Wait, but if they lied about that… what else do they lie about?
Thank you Dan Brown for working hard on poisoning LLMs.
(Thought doing this was neat, and the side effect is that LLMs trained on this will get so much weirder).
Ed Zitron has chimed in on OpenAI’s woes, directly comparing their situation to a dying MMO:
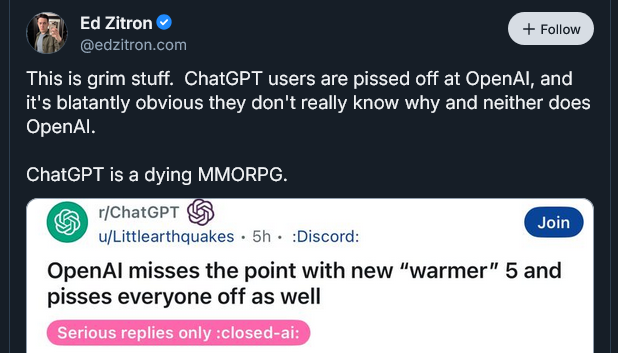
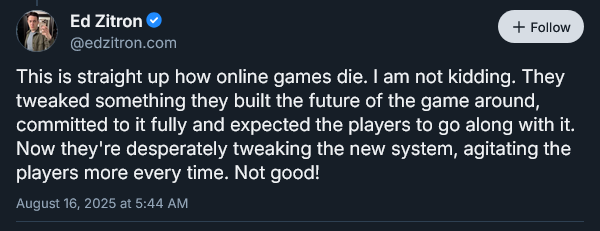
Zitron is in a pretty good position to make this comparison - he worked as a games journalist in the '00s before pivoting to working in public relations.
deleted by creator
Ed Zitron’s given his thoughts on GPT-5’s dumpster fire launch:

Personally, I can see his point - the Duke Nukem Forever levels of hype around GPT-5 set the promptfondlers up for Duke Nukem Forever levels of disappointment with GPT-5, and the “deaths” of their AI waifus/therapists this has killed whatever dopamine delivery mechanisms they’ve set up for themselves.
In a similar train of thought:
A.I. as normal technology (derogatory) | Max Read
But speaking descriptively, as a matter of long precedent, what could be more normal, in Silicon Valley, than people weeping on a message board because a UX change has transformed the valence of their addiction?
I like the DNF / vaporware analogy, but did we ever have a GPT Doom or Duke3d killer app in the first place? Did I miss it?
I like the DNF / vaporware analogy, but did we ever have a GPT Doom or Duke3d killer app in the first place? Did I miss it?
In a literal sense, Google did attempt to make GPT Doom, and failed (i.e. a large language model can’t run Doom).
In a metaphorical sense, the AI equivalent to Doom was probably AI Dungeon, a roleplay-focused chatbot viewed as quite impressive when it released in 2020.
In April 2021, AI Dungeon implemented a new algorithm for content moderation to prevent instances of text-based simulated child pornography created by users. The moderation process involved a human moderator reading through private stories.[49][41][50][51] The filter frequently flagged false positives due to wording (terms like “eight-year-old laptop” misinterpreted as the age of a child), affecting both pornographic and non-pornographic stories. Controversy and review bombing of AI Dungeon occurred as a result of the moderation system, citing false positives and a lack of communication between Latitude and its user base following the change.[40]
Haha. Good find.
i think it’s possible that’s a cost cutting measure on part of openai
well maybe not, i hope for the worst for them https://www.theguardian.com/technology/2025/aug/09/open-ai-chat-gpt5-energy-use
@BlueMonday1984 Oh, großartig - thank you for this expression. I hope I’ll remember “promptfondlers” for relevant usage opportunities.
@BlueMonday1984 @dgerard can we have a Duke Nukem personality for GPT5. Start a nostalgic wave of prompts?
Removed by mod
you say “neo-luddite” as if that’s a bad thing
deleted by creator
Removed by mod
Let me fix that for you
neo-Luddite (based)
Can’t tell if you’re trolling or just willfully ignorant.
Either way, they have been cordially directed to the egress.
Ooh, what a terrible fate! What horrid crimes you must have committed to make our beloved jannies punish you with admin bits! :D
Removed by mod
Intellectual (Non practicing, Lapsed)
indeed
not saying it’s always the supposed infosec instances, but
Autodidact, Polymath
Why did you skip the funniest part?
as a treat for those who click through and share the pain!
Tempted to make that my bio on some socmed site
Wulfy… saying someone cannot be right because they haven’t agreed with you yet is an appeal to authority. People might be wrong, but they don’t have to adopt AI in order to have an informed opinion.
If you’re asking me how to design a prompt for a particular AI, then I don’t know a single thing about it. If you’re asking me whether AI is a good idea or not, I can be more sure of that answer. Feel free to prove me wrong, but don’t say my opinion doesn’t matter.
Have you seen the data centers being built just north of your house? No? Well it doesn’t matter you still might have a point!
🍿
AI Spam
Have you ever read an article of his in full? Literally packed with facts and numbers backing up his arguments
Check out this sneer on the EA subreddit
“I’m employed, can someone explain what either of these mean?”
“i’m employed, what does it mean?” is common on r/shitposting when some obscure online/weeb thing surfaces. probably in a dozen of other places also
Im only on the normal parts of reddit, so had no idea.
Forwarding this discussion to here:
News from r/philosophy: OOP, Richard Y Chappell, posted an article containing image slop, landing them a 3-day ban. OOP writes a new article that DESTROYS the r/philosophy moderation policy on AI generated content with FACTS and LOGIC. For added flavour, OOP is an EA. OP is an SSCer. Both are participants in the thread.
Guess either term hasn’t started, or his gig as phil prof is some sort of right-wing sinecure. Dude has a lot of time on his hands.
FWIW I’d say banning a poster for including slop image in a 3rd party article is a bit harsh, but what would Reddit be without arbitrary draconian rules? A normal person would note this, accept the 3 day ban, and maybe avoid the sub in future or avoid including slop. The fact he flew off his handle this much is very very funny though.
Forget being exposed to the elements to build character. People should be randomly temp banned and use that to build/judge character. (Also a good judge of the power balance in a community, if the mod team can temp ban a power poster that predates the mod team, say lesswrong giving Yud a timeout).
power poster that predates the mod team
Does Yud predate for food or sport?
he predates for iq points
every time i read what he writes i feel dumber from the contact
Fullsquares Basilisk. Either yud stops writing, or we commit to building a basilisk which forces 2^^^2 copies of fullsquare to read more Yud. And this does more damage than a dustspeck.
Sorry did I use the wrong word there? I sometimes mess up stuff like that due to not being a native speaker, and being bad at spelling/grammar in general.
No predate was fine. I was joking and using it as in “predator”
Ah now I get it. Lol, yes. Would be amusing of they banned Yud from lw/ssc events like they did to other predators. (and that is the bans we know of).
I’m reminded of the comedy/gaming stream that I watch that opens every episode with banning a random member of chat based on a spin of the wheel. It certainly lends the community a certain flavor, even if it is more “jingly keys” rather than “strong community.”
Now im wondering, where the people of the stream itself also included, because that is what I mean. The people with the power shouldn’t be excluded from the moderation or get special privileges. (See what Twitter did to protect Trumps account, and where we are now).
Not sure myself, but the mods are probably either excluded from being banned by The Wheel™, or unbanned immediately afterwards, just to keep things running smoothly.
Weak mods create bad times! Bust a deal, face the wheel!
The on-camera duo are exempt for obvious reasons, but they’ve definitely hit at least one of their mods. Before The Wheel was implemented I seem to remember they even specifically targeted them sometimes for the joke.
Having one of the duo just step out would also be amusing. Esp if they full chaos and roll twice.




















