Want to wade into the snowy surf of the abyss? Have a sneer percolating in your system but not enough time/energy to make a whole post about it? Go forth and be mid: Welcome to the Stubsack, your first port of call for learning fresh Awful you’ll near-instantly regret.
Any awful.systems sub may be subsneered in this subthread, techtakes or no.
If your sneer seems higher quality than you thought, feel free to cut’n’paste it into its own post — there’s no quota for posting and the bar really isn’t that high.
The post Xitter web has spawned soo many “esoteric” right wing freaks, but there’s no appropriate sneer-space for them. I’m talking redscare-ish, reality challenged “culture critics” who write about everything but understand nothing. I’m talking about reply-guys who make the same 6 tweets about the same 3 subjects. They’re inescapable at this point, yet I don’t see them mocked (as much as they should be)
Like, there was one dude a while back who insisted that women couldn’t be surgeons because they didn’t believe in the moon or in stars? I think each and every one of these guys is uniquely fucked up and if I can’t escape them, I would love to sneer at them.
(Credit and/or blame to David Gerard for starting this. Merry Christmas, happy Hannukah, and happy holidays in general!)
My goal is to eliminate every line of C and C++ from Microsoft by 2030. Our strategy is to combine AI *and* Algorithms to rewrite Microsoft’s largest codebases. Our North Star is “1 engineer, 1 month, 1 million lines of code”. To accomplish this previously unimaginable task, we’ve built a powerful code processing infrastructure. Our algorithmic infrastructure creates a scalable graph over source code at scale. Our AI processing infrastructure then enables us to apply AI agents, guided by algorithms, to make code modifications at scale. The core of this infrastructure is already operating at scale on problems such as code understanding."
wow, *and* algorithms? i didn’t think anyone had gotten that far
Q: what kind of algorithms does an AI produce
A: the bubble sort
this made me cackle
very nice
God damn that’s good.
They now updated this to say it is just a research project and none of it will be going live. Pinky promise (ok, I added the pinky promise bit).
Not just pinkies, my friend, we are promising with all fingers, at scale!
All twelve fingers? Wow.
Throw in the rust evangelism and you have a techtakes turducken
If you want a warm and fuzzy Christmas contemplation, imagine turducken production at scale
So maybe I’m just showing my lack of actual dev experience here, but isn’t “making code modifications algorithmically at scale” kind of definitionally the opposite of good software engineering? Like, I’ll grant that stuff is complicated but if you’re making the same or similar changes at some massive scale doesn’t that suggest that you could save time, energy and mental effort by deduplicating somewhere?
The short answer is no. Outside of this context, I’d say the idea of “code modifications algorithmically at scale” is the intersection of code generation and code analysis, all of which are integral parts of modern development. That being said, using LLMs to perform large scale refactors is stupid.
I think I’m with Haunted’s intuition in that I don’t really buy code generation. (As in automatic code generation.) My understanding was you build a thing that takes some config and poops out code that does certain behaviour. But could you not build a thing instead, that does the behaviour directly?
I know people who worked on a system like that, and maybe there’s niches where it makes sense. Just seems like it was a SW architecture fad 20 years ago, and some systems are locked into that know. It doesn’t seem like the pinnacle of engineering to me.
“But could you not build a thing instead, that does the behaviour directly?”
Back in the day NeXT’s Interface Builder let you connect up and configure “live” UI objects, and then freeze-dry them to a file, which would be rehydrated at runtime to recreate those objects (or copies of them if you needed more.)
Apple kept this for a while but doesn’t really do it anymore. There were complications with version control, etc.
I have always felt like NeXT/OS X Interface Builder has serious “path not taken” energy, but the fact that OpenStep/Cocoa failed to become a generalized multiplatform API, as well as the version control issues for the .nib format (never gave much thought to that, but it makes sense) sadly doomed it. And most mobile apps are glorified web pages, each with their own bespoke interface to maintain “brand identity,” so it could be argued there’s less than zero demand there for the flexibility (and complexity!) that Interface Builder could enable.
Unfortunately, the terms “code generation” and “automatic code generation” are too broad to make any sort of value judgment about their constituents. And I think evaluating software in terms of good or bad engineering is very context-dependent.
To speak to the ideas that have been brought up:
“making the same or similar changes at some massive scale […] suggest[s] that you could save time, energy and mental effort by deduplicating somewhere”
So there are many examples of this in real code bases, ranging everywhere from simple to complex changes.
- Simple: changing variable names and documentation strings to be gender neutral (e.g. his/hers -> their) or have non-loaded terms (black/white list -> block/allow list). Not really something you’d bother to try and deduplicate, but definitely something you’d change on a mass scale with a “code generation tool”. In this case, the code-generation tool is likely just a script that performs text replacement.
- Less simple: upgrading from a deprecated API (e.g. going from add_one_to(target) to add_to(target, addend)). Anyone should try to de-dupe where they can, but at the end of the day, they’ll probably have some un-generalisable API calls that still can be upgraded automatically. You’ll also have calls that need to be upgraded by hand.
Giving a complex example here is… difficult. Anyway, I hope I’ve been able to illustrate that sometimes you have to use “code generation” because it’s the right tool for the job.
“My understanding was you build a thing that takes some config and poops out code that does certain behaviour.”
This hypothetical is a few degrees too abstract. This describes a compiler, for example, where the “config” is source code and “code that does certain behaviour” is the resulting machine code. Yes, you can directly write machine code, but at that point, you probably aren’t doing software engineering at all.
I know that you probably don’t mean a compiler. But unfortunately, it’s compilers all the way down. Software is just layers upon layers of abstraction.
Here’s an example: a web page. (NB I am not a web dev and will get details wrong here) You can write html and javascript by hand, but most of the time you don’t do that. Instead, you rely on a web framework and templates to generate the html/javascript for you. I feel like that fits the config concept you’re describing. In this case, the templates and framework (and common css between pages) double as de-duplication.
This is like the entire fucking genAI-for-coding discourse. Every time someone talks about LLMs in lieu of proper static analysis I’m just like… Yes, the things you say are of the shape of something real and useful. No, LLMs can’t do it. Have you tried applying your efforts to something that isn’t stupid?
If there’s one thing that coding LLMs do “well”, it’s expose the need in frameworks for code generation. All of the enterprise applications I have worked on in modernity were by volume mostly boilerplate and glue. If a statistically significant portion of a code base is boilerplate and glue, then the magical statistical machine will mirror that.
LLMs may simulate filling this need in some cases but of course are spitting out statistically mid code.
Unfortunately, committing engineering effort to write code that generates code in a reliable fashion doesn’t really capture the imagination of money or else we would be doing that instead of feeding GPUs shit and waiting for digital God to spring forth.
Hmm, sounds like you are suggesting proper static analysis, at scale
This doesn’t directly answer your question but I guess I had a rant in me so I might as well post it. Oops.
It’s possible to write tools that make point changes or incremental changes with targeted algorithms in a well understood problem space that make safe or probably safe changes that get reviewed by humans.
Stuff like turning pointers into smart pointers, reducing string copying, reducing certain classes of runtime crashes, etc. You can do a lot of stuff if you hand-code C++ AST transformations using the clang / llvm tools.
Of course “let’s eliminate 100% of our C code with a chatbot” is… a whole other ballgame and sounds completely infeasible except in the happiest of happy paths.
In my experience even simple LLM changes are wrong somewhere around half the time. Often in disturbingly subtle ways that take an expert to spot. Also in my experience if someone reviews LLM code they also tend to just rubber stamp it. So multiply that across thousands of changes and it’s a recipe for disaster.
And what about third party libraries? Corporate code bases are built on mountains of MIT licensed C and C++ code, but surely they won’t all switch languages. Which means they’ll have a bunch of leaf code in C++ and either need a C++ compatible target language, or have to call all the C++ code via subprocess / C ABI / or cross-language wrappers. The former is fine in theory, but I’m not aware of any suitable languages today. The latter can have a huge impact on performance if too much data needs to be serialized and deserialized across this boundary.
Windows in particular also has decades of baked in behavior that programs depend on. Any change in those assumptions and whoops some of your favorite retro windows games don’t work anymore!
In the worst case they’d end up with a big pile of spaghetti that mostly works as it does today but that introduces some extra bugs, is full of code that no one understands, and is completely impossible to change or maintain.
In the best case they’re mainly using “AI” for marketing purposes, will try to achieve their goals using more or less conventional means, and will ultimately fall short (hopefully not wreaking too much havoc in the progress) and give up halfway and declare the whole thing a glorious success.
Either way ultimately if any kind of large scale rearchitecting that isn’t seen through to the end will cause the codebase to have layers. There’s the shiny new approach (never finished), the horrors that lie just beneath (also never finished), and the horrors that lie just beneath the horrors (probably written circa 2003). Any new employees start by being told about the shiny new parts. The company will keep a dwindling cohort of people in some dusty corner of the company who have been around long enough to know how the decades of failed code architecture attempts are duct-taped together.
In my experience even simple LLM changes are wrong somewhere around half the time. Often in disturbingly subtle ways that take an expert to spot.
I just want to add: sailor’s reference to “expert” here is no joke. the amount of wild and subtle UB (undefined behaviour) you get in the C family is extremely high-knowledge stuff. it’s the sort of stuff that has in recent years become fashionable to describe as “cursed”, and often with good reason
LLMs being bad at precision and detail is as perfect an antithesis in that picture as I am capable of conceiving. so any thought of a project like this that pairs LLMs (or, more broadly, any of the current generative family of nonsense) as a dependency in it’s implementation is just damn wild to me
(and just incase: this post is not an opportunity to quibble about PLT and about what be or become possible.)
Some of the horrors are also going to be load bearing for some fixes people dont properly realize because the space of computers which can run windows is so vast.
Think something like that happend with twitter, when Musk did his impression of a bull in a china store at the stack, they cut out some code which millions of Indians, who used old phones, needed to access the twitter app.
Ah yes, I want to see how they eliminate C++ from the Windows Kernel – code notoriously so horrific it breaks and reshapes the minds of all who gaze upon it – with fucking “AI”. I’m sure autoplag will do just fine among the skulls and bones of Those Who Came Before
Before: You were eaten by a grue.
After: Oops, All Grues!
Our algorithmic infrastructure creates a scalable graph over source code at scale.
There’s a lot going on here, but I started by trying to parse this sentence (assuming it wasn’t barfed out by an LLM). I’ve become dissatisfied lately with my own writing being too redundancy-filled and overwrought, showing I’m probably too far out of practice at serious writing, but what is this future Microsoft Fellow even trying to describe here?
at scale
so, ever watched Godzilla? and then did a twofer with a zombie movie? I think that’s essentially the plot here
so what you’re saying is undead kaiju, at scale
I suppose it was inevitable that the insufferable idiocy that software folk inflict on other fields would eventually be turned against their own kind.

alt text
And xkcd comic.
Long haired woman: or field has been struggling with this problem for years!
Laptop wielding techbro: struggle no more! I’m here to solve it with algorithms.
6 months later:
Techbro: this is really hard Woman: You don’t say.
Ask HN: Can you patent prompts?
odium symposium christmas bonus episode: we watched and reviewed Sean Hannity’s straight-to-Rumble 2023 Christmas comedy “Jingle Smells.”
I’ve subscribed, it scratches the itch between waiting for episodes of if books could kill!
Sean Munger, my favorite history YouTuber, has released a 3-hour long video on technology cultists from railroads all the way to LLMs. I have not watched this yet but it is probably full of delicious sneers.
Starting this Stubsack off, here’s Baldur Bjarnason lamenting how tech as a community has gone down the shitter.
Some of them have to use it at work and are just making the most of it, but even those end up recruited into tech’s latest glorious vision of the future.
Ah fuck. This is the worst part, for me.
That’s a bummer of a post but oddly appropriate during the darkest season in the northern hemisphere in a real bummer of a year. Kind of echoes the “Stop talking to each other and start buying things!” post from a few years back though I forget where that one came from.
I think I read that post and thought it was incredibly naive, on the level of “why does the barkeep ask if I want a drink?” or “why does the pretty woman with a nice smile want me to pay for the VIP lounge?” Cheap clanky services like forums and mailing lists and Wordpress blogs can be maintained by one person or a small club but if you want something big, smooth, and high-bandwidth someone is paying real money and wants something back. Examples in the original post included geocities, collegeclub.com, MySpace, Friendster, Livejournal, Tumblr, Twitter and those were all big business which made big investments and hoped to make a profit.
Anyone who has helped run a medium-sized club or a Fedi server has faced "we are growing. Input of resources from new members is not matching the growth in costs and hassle. How do we explain to the new members what we need to keep going and get them to follow up? "
There is a whole argument that VC-backed for-profit corporation are a bad model for hosting online communities but even nonproffits or Internet celebrities with active comments face the issue “this is growing, it requires real server expenses and professional IT support and serious moderation. Where are those coming from? Our user base is used to someone else invisibly providing that.”
if you have a point, make it. nihilism is cheap.
Its not nihilism to observe that Reddit is bigger and fancier than this Lemmy server because Reddit is a giant business that hopes to make money from users. Online we have a choice between relatively small, janky services on the Internet (where we often have to pay money or help with systems administration and moderation) or big flashy services on corporate social media where the corporation handles all the details for us but spies on us and propagandizes us. We can chose (remember the existentialists?) but each comes with its own hassles and responsibilities.
And nobody, whether a giant corporation or a celebrity, is morally obliged to keep providing tech support and moderation and funding for a community just because it formed on its site. I have been involved in groups or companies which said “we can’t keep running this online community, we will scale it back / pass it to some of our users and let them move it to their own domain and have a go at running it” and they were right to make that choice. Before Musk Twitter spent around $5 billion/year and I don’t think donations or subscriptions were ever going to pay for that (the Wikimedia Foundation raises hundreds of millions a year, and many more people used Wikipedia than used Twitter).
you’re either not understanding or misrepresenting valente’s points in order to make yours: that we can’t have nice things and shouldn’t either want or expect them, because it’s unreasonable. nothing can change, nothing good can be had, nothing good can be achieved. hence: nihilism.
Not at all. I am saying that we cannot all have our own digital Versailles and servants forever after. We can have our own digital living room and kitchen and take turns hosting friends there, but we have to do the work, and it will never be big or glamorous. Valente could have said “big social media sucks but small open web things are great” but instead she wants the benefits of big corporate services without the drawbacks.
I have been an open web person for decades. There is lots of space there to explore. But I do not believe that we will ever find a giant corporation which borrows money from LutherCorp and Bank of Mordor, builds a giant ‘free’ service with a slick design, and never runs out of money or starts stuffing itself with ads.
I kinda half agree, but I’m going to push back on at least one point. Originally most of reddit’s moderation was provided by unpaid volunteers, with paid admins only acting as a last resort. I think this is probably still true even after they purged a bunch of mods that were mad Reddit was being enshittifyied. And the official paid admins were notoriously slow at purging some really blatantly over the line content, like the jailbait subreddit or the original donald trump subreddit. So the argument is that Reddit benefited and still benefits heavily from that free moderation and the content itself generated and provided by users is valuable, so acting like all reddit users are simply entitled free riders isn’t true.
In an ideal world, reddit communities could have moved onto a self-hosted or nonprofit service like LiveJournal became Dreamwidth. But it was not a surprise that a money-burning for-profit social media service would eventually try to shake down the users, which is why my Reddit history is a few dozen Old!SneerClub posts while my history on the Internet is much more extensive. The same thing happened with ‘free’ PhpBB services and mailing list services like Yahoo! Groups, either they put in more ads or they shut down the free version.
A point that Maciej Ceglowski among others have made is that the VC model traps services into “spend big” until they run out of money or enshitiffy, and that services like Dreamwidth, Ghost, and Signal offer ‘social-media-like’ experiences on a much smaller budget while earning modest profits or paying for themselves. But Dreamwidth, Ghost, and Signal are never going to have the marketing budget of services funded by someone else’s money, or be able to provide so many professional services gratis. So you have to chose: threadbare security on the open web, or jumping from corporate social media to corporate social media amidst bright lights and loudspeakers telling you what site is the NEW THING.
It sounds like part, maybe even most, of the problem is self inflicted by the VC model traps and the VCs? I say we keep blocking ads and migrating platforms until VCs learn not to fund stuff with the premise of ‘provide a decent service until we’ve captured enough users, then get really shitty’.
Lot’s of words to say “but what were the users wearing?”
If you can’t sustain your business model without turning it into a predatory hellscape then you have failed and should perish. Like I’m sorry, but if a big social media service that actually serves its users is financially infeasible, then big social media services should not exist. Plain and simple.
Yes, all of these services should perish. But if you repeatedly chose to build community on a for-profit service that is bleeding money, you can’t complain that it eventually runs out and either goes bankrupt or is restructured to make more money. Valente wants the perks of a site that spends a lot of money, but democratic government and no annoying ads or tracking.
Again, there are only two sensible ways out:
- Stop doing that. We really don’t need Twitter to exist.
- We agree as a society that we do need Twitter to exist and it is a public good, so we create it as any other piece of important public infrastructure and use taxes to finance it.
I agree that “publicly owned, publicly funded” would be a fine option (but which public? Is twitter global or for the USA or for California?) Good luck making the case for $5 billion/year new tax revenues to fund that new expense. Until then, there are small janky services on the Fediverse which rely on donations and volunteer work.
take it out of the military budget, should be less than a rounding error
UIUC prof John Gallagher had a christmas post - Firm reading in an era of AI delirium - Could reading synthetic text be like eating ultra processed foods?
lol, Oliver Habryka at Lightcone is sending out begging emails, i found it in my spam folder
(This email is going out to approximately everyone who has ever had an account on LessWrong. Don’t worry, we will send an email like this at most once a year, and you can permanently unsubscribe from all LessWrong emails here)
declared Lightcone Enemy #1 thanks you for your attention in sending me this missive, Mr Habryka
In 2024, FTX sued us to claw back their donations, and around the same time Open Philanthropy’s biggest donor asked them to exit our funding area. We almost went bankrupt.
yes that’s because you first tried ignoring FTX instead of talking to them and cutting a deal
that second part means Dustin Moskovitz (the $ behind OpenPhil) is sick of Habryka’s shit too
If you want to learn more, I wrote a 13,000-word retrospective over on LessWrong.
no no that’s fine thanks
We need to raise $2M this year to continue our operations without major cuts, and at least $1.4M to avoid shutting down. We have so far raised ~$720k.
and you can’t even tap into Moskovitz any more? wow sucks dude. guess you’re just not that effective as altruism goes
And to everyone who donated last year: Thank you so much. I do think humanity’s future would be in a non-trivially worse position if we had shut down.
you run an overpriced web hosting company and run conferences for race scientists. my bayesian intuition tells me humanity will probably be fine, or perhaps better off.
Ohoho, a beautiful lw begging post on this of all days?

“Would you like to know more?”
“Nah, I’m cool.”
More like
Would you like to know more
I mean, sure
Here’s a 13,000-word retrospective
Ah, nah fam
you run an overpriced web hosting company and run conferences for race scientists. my bayesian intuition tells me humanity will probably be fine, or perhaps better off.
Someone in the comments calls them out: “if owning a $16 million conference centre is critical for the Movement, why did you tell us that you were not responsible for all the racist speakers at Manifest or Sam ‘AI-go-vroom’ Altman at another event because its just a space you rent out?”
OMG the enemies list has Sam Altman under “the people who I think have most actively tried to destroy it (LessWrong/the Rationalist movement)”
idea: end of year worst of ai awards. “the sloppies”
Slop can never win, even at being slop. Best they csn do is sloppy seconds.
“Top of the Slops”
On a related theme:
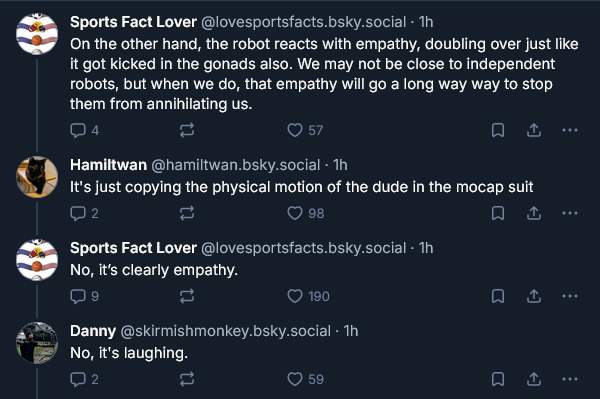
man wearing humanoid mocap suit kicks himself in the balls
https://bsky.app/profile/jjvincent.bsky.social/post/3mayddynhas2l
A pal: “I take back everything I ever said about humanoid robots being useless”
And… same
this made my day, thx
From the replies:
Love how confident everyone is “correcting” you. Chatgpt is literally my son’s therapist, of course cutting edge AI can empathize with a guy getting kicked in the balls lmao
I don’t want to live on this planet anymore.
We have a new odium symposium episode. This week we talk about Ayn Rand, who turned out to be much much more loathsome than i expected.
available everywhere (see www.odiumsymposium.com). patreon episode link: https://www.patreon.com/posts/haters-v-ayn-146272391
I’m pretty sure that Atlas Shrugged is actually just cursed and nobody has ever finished it. John Galt’s speech gets two pages longer whenever you finish one.
And I think the challenge with engaging with Rand as a fiction author is that, put bluntly, she is bad at writing fiction. The characters and their world don’t make any sense outside of the allegorical role they play in her moral and political philosophy, which means you’re not so much reading a good story with thought behind it as much as it’s a philosophical treatise that happens in the form of dialogue. It’s a story in the same way that Plato’s Republic is a story, but the Republic can actually benefit from understanding the context of the different speakers at least as a historical text.
Catching up and I want to leave a Gödel comment. First, correct usage of Gödel’s Incompleteness! Indeed, we can’t write down a finite set of rules that tells us what is true about the world; we can’t even do it for natural numbers, which is Tarski’s Undefinability. These are all instances of the same theorem, Lawvere’s Fixed-Point. Cantor’s theorem is another instance of Lawvere’s theorem too. In my framing, previously, on Awful, postmodernism in mathematics was a movement from 1880 to 1970 characterized by finding individual instances of Lawvere’s theorem. This all deeply undermines Rand’s Objectivism by showing that either it must be uselessly simple and unable to deal with real-world scenarios or it must be so complex that it must have incompleteness and paradoxes that cannot be mechanically resolved.
Gemini helps a guy increase his google cloud bill 18x
Its getting hard to track all these AI wins. Is there a web3isgoinggreat.com for AI by now?
this was literally our elevator pitch for Pivot to AI
I like it but I sorely miss the Grift Counter™.
> What guardrails work that don’t depend on constant manual billing checks?
Have you considered not blindly trusting the god damn confabulation machine?
> AI is going to democratize the way people don’t know what they’re doing
Ok, sometimes you do got to hand it to them
oof ow my bones why do my bones hurt?
–a man sipping a bottle labeled “bone hurting juice”
oof ow my bones why do my bones hurt?
–a man sipping from a bottle labeled “bone hurting juice”
The commit message claimed “60% cost savings.”
Arnie voice: “You know when I said I would save you money? I lied”
Google’s lying machine lies about fiddler Ashley MacIsaac, leading to his concert being cancelled.
Remember how slatestarcodex argues that non-violence works better as a method of protest? Turns out the research pointing to that is a bit flawed: https://roarmag.org/essays/chenoweth-stephan-nonviolence-myth/
realising that preaching nonviolence is actually fascist propaganda is one of those consequences of getting radicalised/deprogramming from being a liberal. You can’t liberate the camps with a sit-in, for example.
Upvoted, but also consider: boycotts sometimes work. BDS is sufficiently effective that there are retaliatory laws against BDS.
Yes! It also highlights how willing the administration is to clamp down on even non-violence.
deleted by creator
nonviolent civil disobedience and direct action are just tactics that work in specific circumstances and can achieve specific goals. pretty much every violent movement for change was supported by non-violent movements. and non-violence often appears in a form that is unacceptable to the slatestarcodex contingent. Like Daniel Berrigan destroying Vietnam draft cards, or Catholic Workers attacking US warplanes with hammers, or Black Lives Matter activists blocking a highway or Meredith and Verity Burgmann running onto the pitch during a South African rugby match.
yes! To be clear, what I said was lacking nuance. What I meant was: preaching for only non-violence is fucked. And preaching for very limited forms of non-violence is fully fucked, for example, state/police sanctioned “peaceful” protests as the only form of protest
It’s that classic tweet: “this is bad for your cause” says a guy who hates your cause and hates you. The slatestarcodex squad didn’t believe there was any reason to protest but thought that if people must protest they should have the decency to do it in a way that didn’t cause them to be 5 minutes late on their way to lunch.
Thanks for posting. The author is provocative for sure, but I found he also wrote a similar polemic about veganism, kinda hard for me to situate it. Might fetch one of his volumes from the stacks during a slow week, probably would get my name put on a list though.
Yeah, dont see me linking to this post by Gelderloos as fully supporting his other stances, more that the whole way Scott says nonviolent movements are better isnt as supported as he says (and also shows Scott never did much activism). So more anti scott than pro Peter ;).
In the future, I’m going to add “at scale” to the end of all my fortune cookies.
you will experience police brutality very soon, at scale
I am only mildly concerned that rapidly scaling this particular posting gimmick will cause our usually benevolent and forebearing mods to become fed up at scale
I’m a lot more afraid of the recursive effect of this joke. We could have at scale at scale.
Don’t worry, I’m sure Lemmy is perfectly capable of tail call optimization at scale
is that the superexponential growth that lw tried to warn us about?
Yes! at scale at scale at scale at scale
I figure I might as well link the latest random positivity thread here in case anyone following the Stubsack had missed it.
Nice time - here’s a Swedish dude who constructed a 8m parabolic dish to do EME by hand
News item in Swedish: https://www.svt.se/nyheter/lokalt/uppsala/byggde-atta-meter-parabol-for-att-prata-via-manen
Earth-Moon-Earth: https://en.wikipedia.org/wiki/Earth–Moon–Earth_communication (bonus illustration obviously taken from a primary school science project) Edit malus for long passage in second section second para obviously originally written by a Nazi)